Bridging maSigPro Analysis
Guide to applying maSigPro workflow with scMaSigPro
Priyansh Srivastava
Source:vignettes/scMaSigPro-maSigPro.Rmd
scMaSigPro-maSigPro.RmdAbstract
scMaSigPro is an R package designed for the serial
analysis of single-cell RNA-seq (scRNA-Seq) data along inferred
pseudotime. It builds upon the maSigPro
Bioconductor package to identify genes with significant expression
changes across different branching paths in a pseudotime-ordered
scRNA-Seq dataset. This vignette illustrates the workflow of the
original maSigPro
Bioconductor package of using scMaSigPro.
Introduction
scMaSigPro is a polynomial regression-based approach
inspired by the maSigPro
Bioconductor package tailored for scRNA-Seq data. It first discretizes
single cell expression along inferred pseudotime while preserving order.
Afterwards it applies the maSigPro
model to pinpoint genes exhibiting significant expression profile
differences among branching paths and pseudotime.
Overview of maSigPro
maSigPro (microarray significant profiles) is a bioconductor package. Originally designed for microarray data analysis, maSigPro focuses on identifying genes with significant expression profiles that vary among different experimental groups, particularly in time-course experiments.
Adaptation for Bulk-RNA Seq Data
In 2016, the maSigPro package was adapted for bulk-RNA seq data, a crucial development given the distinct differences between microarray and RNA-Seq technologies. Unlike the distributions typically seen in microarray data, bulk-RNA Seq data generally follows a Negative Binomial Distribution, which is more apt for count data like RNA-Seq, characterized by variance often exceeding the mean.
This adaptation brought in explicit theta parameterization, critical
for RNA-Seq data analysis as the theta parameter represents the
dispersion in the Negative Binomial Distribution. Such parameterization
enhances the accuracy in modeling gene expression variability, a key
factor in identifying significant changes in gene expression, thereby
marking a significant step forward in the application of
maSigPro to the more complex RNA-Seq data.
Installation
Currently, scMaSigPro is available on GitHub and can be
installed as follows:
Bioconductor and Dependencies
# Install Dependencies
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(version = "3.14")
BiocManager::install(c('SingleCellExperiment', 'maSigPro', 'MatrixGenerics', 'S4Vectors'))scMaSigPro latest version
To install scMaSigPro from GitHub, use the following R
code:
# Install devtools if not already installed
if (!requireNamespace("devtools", quietly = TRUE)) {
install.packages("devtools")
}
# Install scMaSigPro
devtools::install_github("BioBam/scMaSigPro",
ref = "main",
build_vignettes = FALSE,
build_manual = TRUE,
upgrade = "never",
force = TRUE,
quiet = TRUE)Installing maSigPro
You can easily install maSigPro from Bioconductor using
the following steps:
# Install Bioconductor if not already installed
if (!require("BiocManager", quietly = TRUE)) {
install.packages("BiocManager")
}
# install maSigPro
BiocManager::install("maSigPro")Setup
First, we need to load both scMaSigPro and
maSigPro. Additionally, we will load testthat,
a user-friendly testing framework for R that integrates well with
existing workflows. We will use testthat to verify if
scMaSigPro produces the same results as
maSigPro when used in bulk mode.
# load scMaSigPro
library(scMaSigPro)
# load maSigPro
library(maSigPro)
# We will also keep checking the output
library(testthat)Setting up the data
In this tutorial, we will use datasets from maSigPro and
aim to replicate the same analysis pipeline using
scMaSigPro. For more detailed information about the data
analysis, refer to the original maSigPro
vignette-userguide
# load counts
data(data.abiotic)
# load Design file
data(edesign.abiotic)
# save with different names for scMaSigPro
count <- data.abiotic
metadata <- as.data.frame(edesign.abiotic)Let’s briefly examine each dataset:
## Control_3H_1 Control_3H_2 Control_3H_3 Control_9H_1 Control_9H_2
## STMDF90 0.13735714 -0.3653065 -0.15329448 0.44754535 0.287476796
## STMCJ24 NA NA NA NA NA
## STMJH42 0.07864449 0.1002328 -0.17365488 -0.25279484 0.184855409
## STMDE66 0.22976991 0.4740975 0.46930716 0.37101059 -0.004992029
## STMIX74 0.14407618 -0.4801864 -0.07847999 0.05692331 0.013045420## Time Replicate Control Cold Heat
## Control_3H_1 3 1 1 0 0
## Control_3H_2 3 1 1 0 0
## Control_3H_3 3 1 1 0 0
## Control_9H_1 9 2 1 0 0
## Control_9H_2 9 2 1 0 0In edesign.abiotic, there are four groups, including one control group. The experiment features experimental capture times, which are distinct from Pseudotime, and includes temporal replicates.
To simplify the analysis, we’ll convert the binarized groups into a
single column. scMaSigPro automatically binarizes groups
internally, reducing the likelihood of errors.
# Add group column
metadata$Group <- apply(metadata[, c(3:6)], 1, FUN = function(x) {
return(names(x[x == 1]))
})
# Remove binary columns
metadata <- metadata[, !(colnames(metadata) %in%
c("Control", "Cold", "Heat", "Salt")),
drop = FALSE
]
# View
print(metadata[c(1:5), ])## Time Replicate Group
## Control_3H_1 3 1 Control
## Control_3H_2 3 1 Control
## Control_3H_3 3 1 Control
## Control_9H_1 9 2 Control
## Control_9H_2 9 2 ControlCreating objects for scMaSigPro
scMaSigPro utilizes S4 classes, and therefore, the
initial step involves creating an object of the scMaSigPro
class, also known as scmpObject. To do this, we use the
create_scmp() function. We will use the same object
throughout the tutorial to show the concept of S4 classes. On the other
hand for maSigPro we will be making different S3 objects as
shown in the `original
tutorial.
As we are using scMaSigPro in bulk mode, we will set
use_as_bin = TRUE. This directs the data to the dense slot of the
scmpObject, allowing us to proceed with the analysis without using
sc.squeeze(), which is specifically designed for scRNA-Seq
pseudo-bulking.
scmp_ob <- create_scmp(
counts = count,
cell_data = metadata,
ptime_col = "Time",
path_col = "Group",
use_as_bin = TRUE
)
# Print Console output
scmp_ob## Class: ScMaSigProClass
## nCells: 36
## nFeatures: 1000
## Pseudotime Range: 3 27
## Branching Paths: Control, Cold, Heat, Salt
## Binned Pseudotime: 3-27(Range), 13(Mean),
## Number of bins-> Cold: 9 Control: 9 Heat: 9 Salt: 9
## Average bin Size-> Cold: 1 Control: 1 Heat: 1 Salt: 1In the console output, we can observe that the data has been
transferred to the dense slot. We can visualize this using
plotBinTile().
plotBinTile(scmp_ob)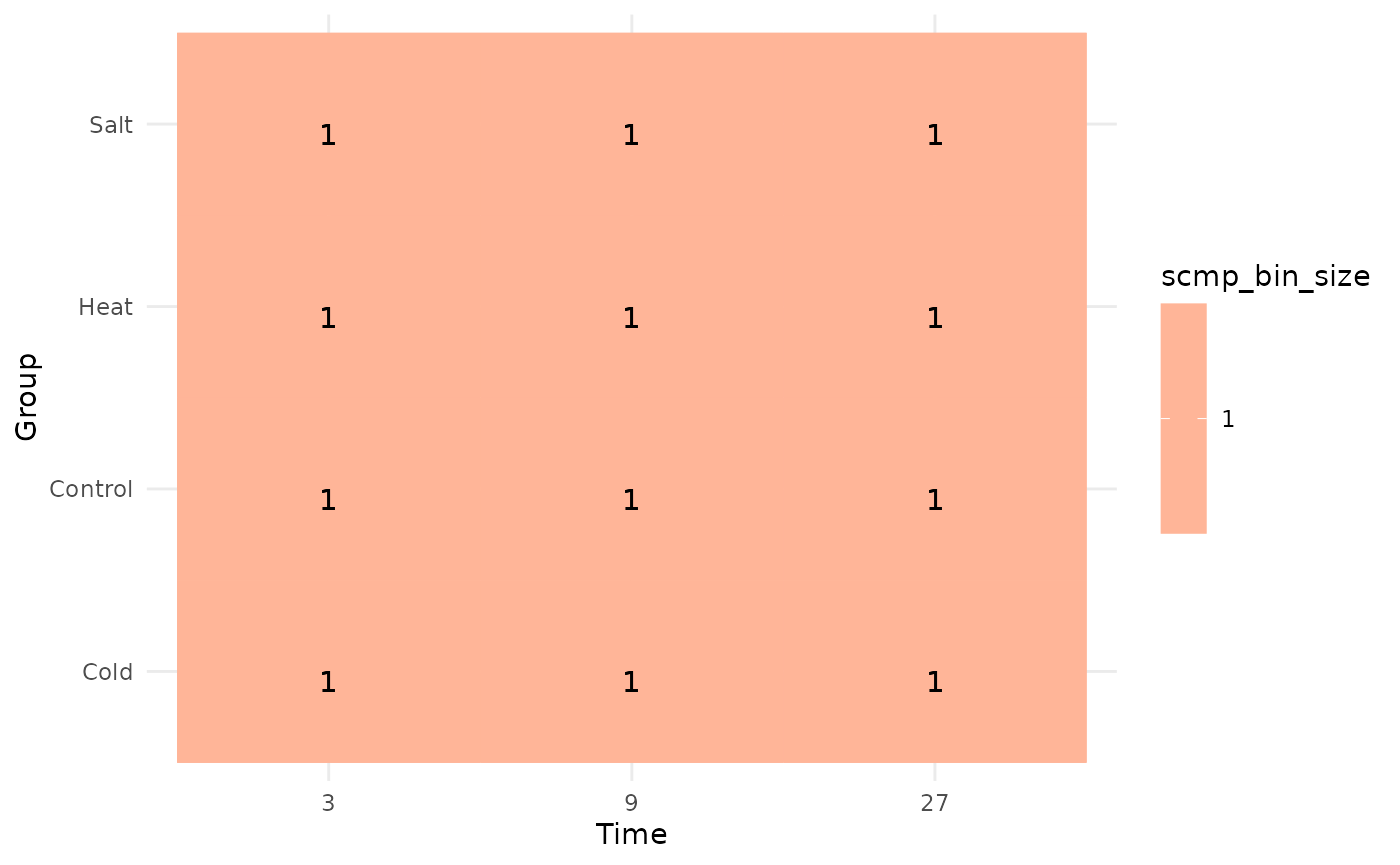
Next, we need to verify if scMaSigPro has created the
appropriate count matrix. For this, we will use
testthat::expect_identical(). This function highlights any
mismatches; if everything is identical, it will not throw an error. The
eDense() function retrieves the dense expression file from
the scMaSigPro object.
expect_identical(
object = as.data.frame(eDense(scmp_ob)),
expected = data.abiotic
)No errors were thrown, indicating that our setup is correct and we can proceed with the analysis.
Creatin of Regression Matrix
The function maSigPro::make.design.matrix() is used to
create a regression matrix for fitting the full regression model. In
scMaSigPro, this task is accomplished using
sc.set.poly(), where the regression matrix is referred to
as “predictor_matrix”. We will also verify that scMaSigPro
has correctly performed binarization, as specified in
edesign.abiotic.
maSigPro::make.design.matrix() and
scMaSigPro::sc.set.poly()
# Using maSigPro
design <- make.design.matrix(edesign.abiotic, degree = 2)
# Using scMaSigPro
scmp_ob <- sc.set.poly(scmp_ob, poly_degree = 2)
# Comparing binarization results
expect_equal(pathAssign(scmp_ob), expected = edesign.abiotic)
# Comparing regression matrices
expect_identical(scmp_ob@Design@predictor_matrix, expected = design$dis)No errors were thrown, so we can proceed with the analysis.
Detecting Non-Flat Profiles with
maSigPro::p.vector()
To compute a regression fit for each gene, maSigPro uses
p.vector(), while scMaSigPro uses
sc.p.vector(). The main difference is the offset parameter
in scMaSigPro, which accounts for variations in bin sizes.
Since we are not dealing with scRNA-Seq data, we will disable this
parameter.
# Using maSigPro
gc <- capture_output(fit <- p.vector(data.abiotic, design,
Q = 0.05,
MT.adjust = "BH", min.obs = 20
))
# Using ScMaSigPro
scmp_ob <- sc.p.vector(scmp_ob,
min_na = 20,
verbose = FALSE,
link = "identity",
offset = FALSE,
max_it = 25,
epsilon = 0.00001,
family = gaussian()
)Now, we’ll compare the S3 object
fit frommaSigPro::p.vector()with the results fromsc.p.vector()`:
# Compare p-values
expect_identical(
matrix(scmp_ob@Profile@p_values,
dimnames = list(names(scmp_ob@Profile@p_values), "p.value")
),
expected = as.matrix(fit$p.vector[, 1, drop = FALSE])
)
# Compare adjusted p-values
pad <- scmp_ob@Profile@adj_p_values
names(pad) <- NULL
expect_identical(pad, expected = fit$p.adjusted)Detecting Significant Polynomial Terms with
maSigPro::T.fit()
Next, we apply a variable selection procedure to identify significant
polynomial terms for each gene, using T.fit() and
sc.t.fit().
# Using maSigPro
gc <- capture_output(tstep <- T.fit(fit, step.method = "backward", alfa = 0.05))
# Using scMaSigPro
scmp_ob <- sc.t.fit(scmp_ob,
offset = FALSE,
verbose = FALSE,
epsilon = 0.00001,
family = gaussian()
)We will compare the s3 object tstep from
maSigPro::T.fit() with the results from
sc.t.fit():
# Solutions
expect_identical(showSol(scmp_ob), expected = tstep$sol)
# Coefficients
expect_identical(showCoeff(scmp_ob), expected = tstep$coefficients)
# Group Coefficients
expect_identical(showGroupCoeff(scmp_ob), expected = tstep$group.coeffs)
# tscore
expect_identical(as.data.frame(showTS(scmp_ob)), expected = tstep$t.score)R-Square Filter with maSigPro::get.siggenes()
The next step is to generate lists of significant genes based on
desired biological question. This is achieved using the
get.siggenes() function in maSigPro and
sc.filter() in scMaSigPro.
# maSigPro
sigs <- get.siggenes(tstep, rsq = 0.6, vars = "groups")
# scMaSigPro
scmp_ob <- sc.filter(scmp_ob, rsq = 0.6, vars = "groups")We’ll compare the s3 object (sigs) from `maSigPro::get.siggenes()’ with the results from sc.filter()’:
# Compare Cold vs Control
expect_identical(scmp_ob@Significant@genes$ColdvsControl,
expected = sigs$summary$ColdvsControl
)
# Compare Heat vs Control
expect_identical(scmp_ob@Significant@genes$HeatvsControl,
expected = sigs$summary$HeatvsControl[sigs$summary$HeatvsControl != " "]
)
# Compare Salt vs Control
expect_identical(scmp_ob@Significant@genes$SaltvsControl,
expected = sigs$summary$SaltvsControl[sigs$summary$SaltvsControl != " "]
)
# Compare Control
expect_identical(scmp_ob@Significant@genes$Control,
expected = sigs$summary$Control[sigs$summary$Control != " "]
)All comparisons indicate equality, confirming that the results are reproducible up to this point.
Visualizing the trends and Intersection
Having confirmed that the numerical values are identical for both methods, our next step is to assess whether the actual trends are also consistent.
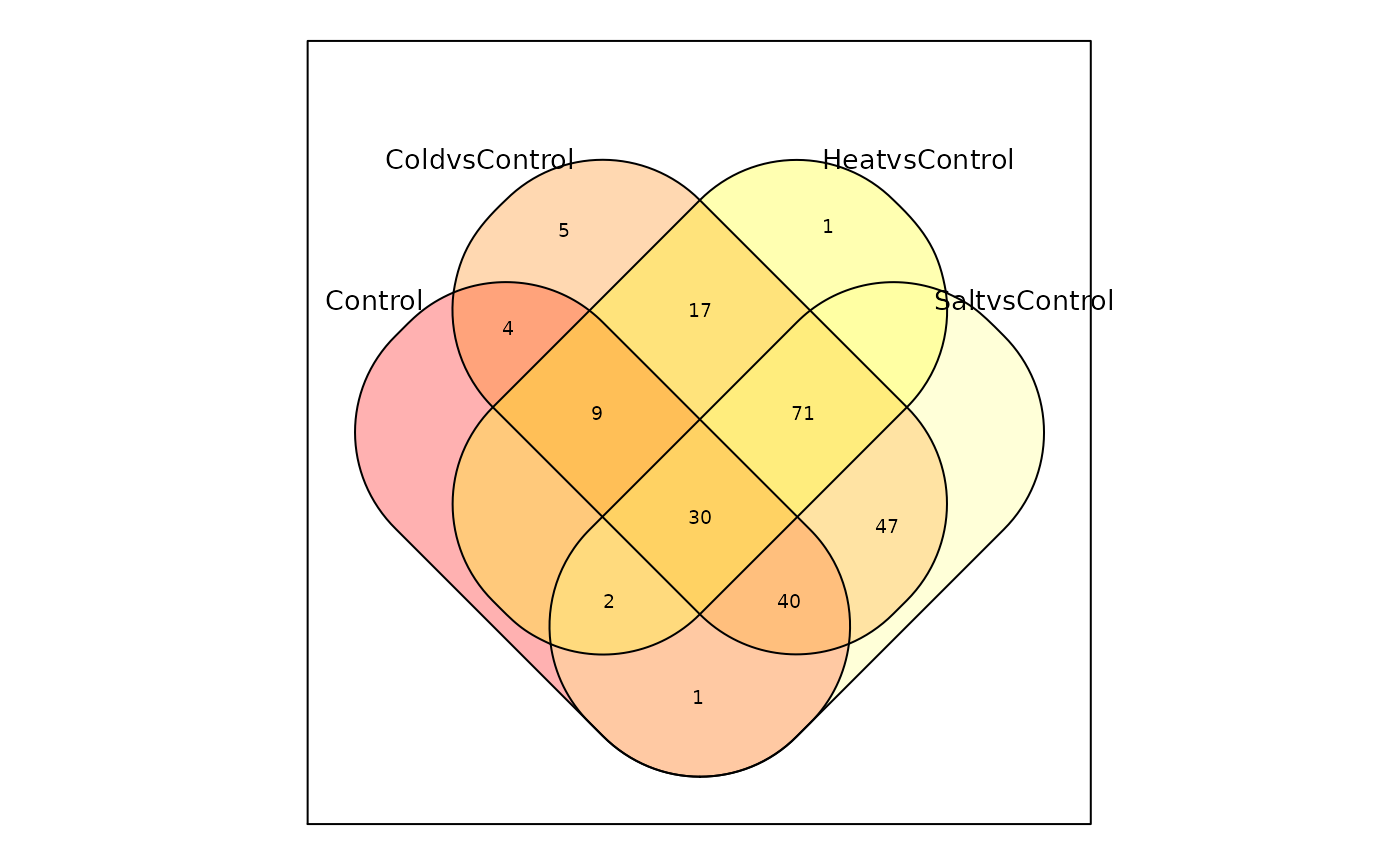
Visualizing Intersection maSigPro::suma2Venn()
# Venn Diagram of maSigPro
suma2Venn(sigs$summary[, c(1:4)])
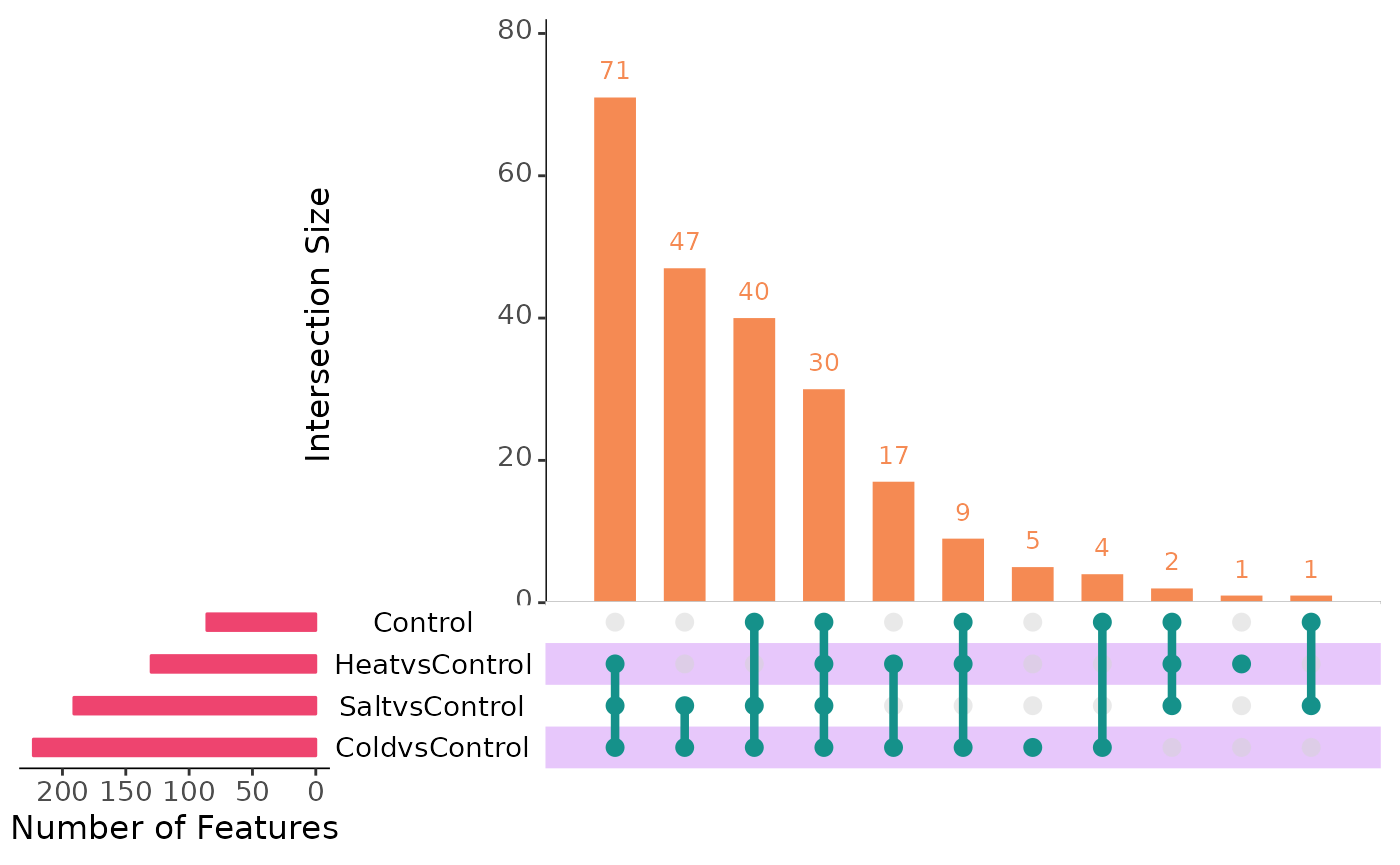
# Upset plot of scMaSigPro
plotIntersect(
scmpObj = scmp_ob,
min_intersection_size = 0
)
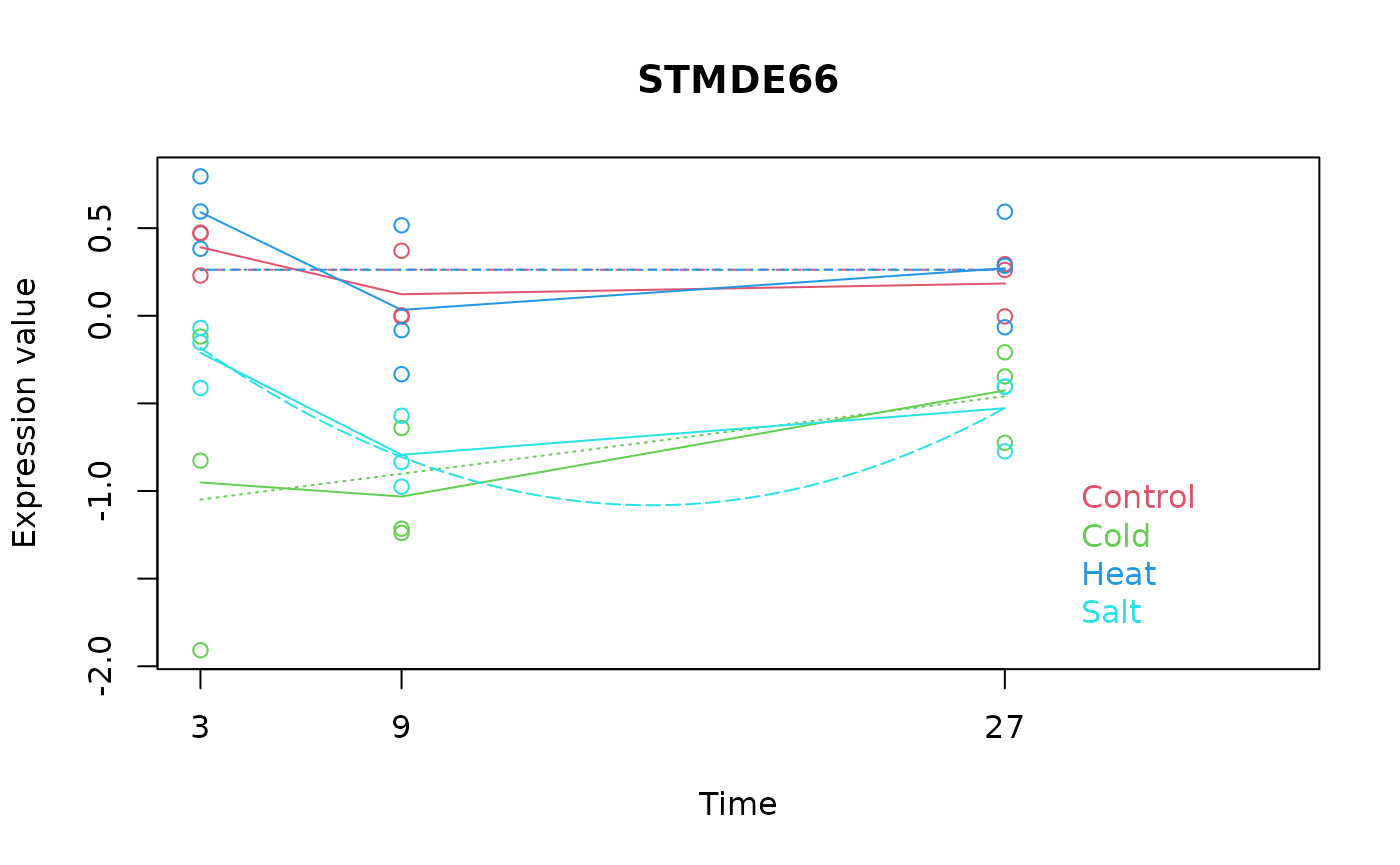
Visualizing Single trend with
maSigPro::PlotGroups()
The PlotGroups() function in maSigPro
generates a plot of gene expression profiles with time as the x-axis and
gene expression on the y-axis. In these plots, gene expression from the
same experimental group is represented in the same color, and lines are
drawn to join the averages of each time-group to visualize the trend of
each group over time. For scMaSigPro, this functionality is
achieved using plotTrend().
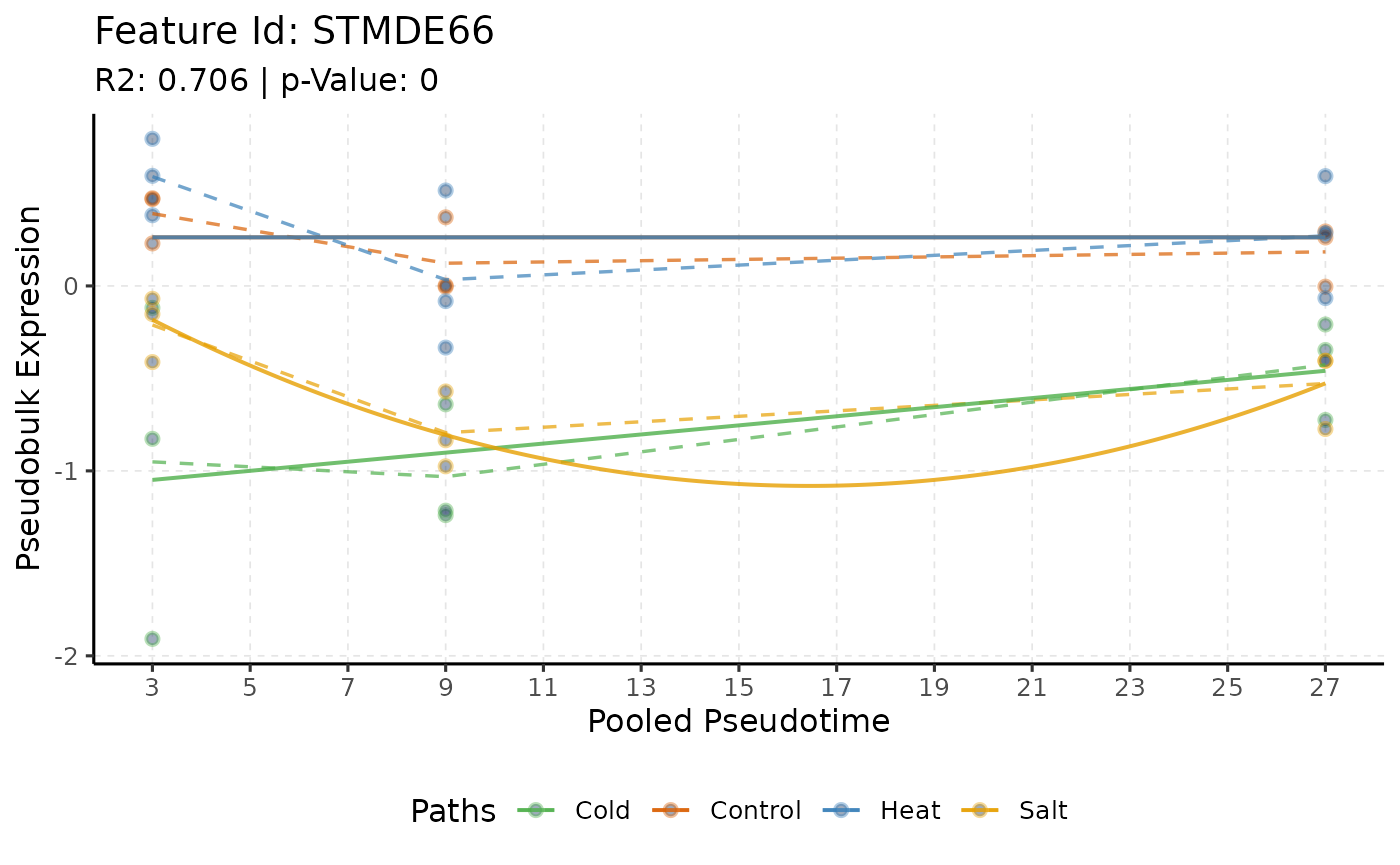
# Extracting gene "STMDE66" from data
STMDE66 <- data.abiotic[rownames(data.abiotic) == "STMDE66", ]
# Plotting with maSigPro
PlotGroups(STMDE66,
edesign = edesign.abiotic, show.fit = TRUE,
dis = design$dis, groups.vector = design$groups.vector
)
# Plotting the same gene with scMaSigPro
plotTrend(scmp_ob, "STMDE66",
logs = FALSE, pseudoCount = 0,
smoothness = 0.01, significant = FALSE,
summary_mode = "mean",
curves = TRUE, lines = TRUE, points = TRUE
)
Visualizing Cluster trend with
maSigPro::PlotProfiles()
# Plot clustered Trend
gc <- capture_output(
res <- see.genes(sigs$sig.genes$ColdvsControl,
show.fit = TRUE, dis = design$dis,
cluster.method = "hclust", cluster.data = 1, k = 9
)
)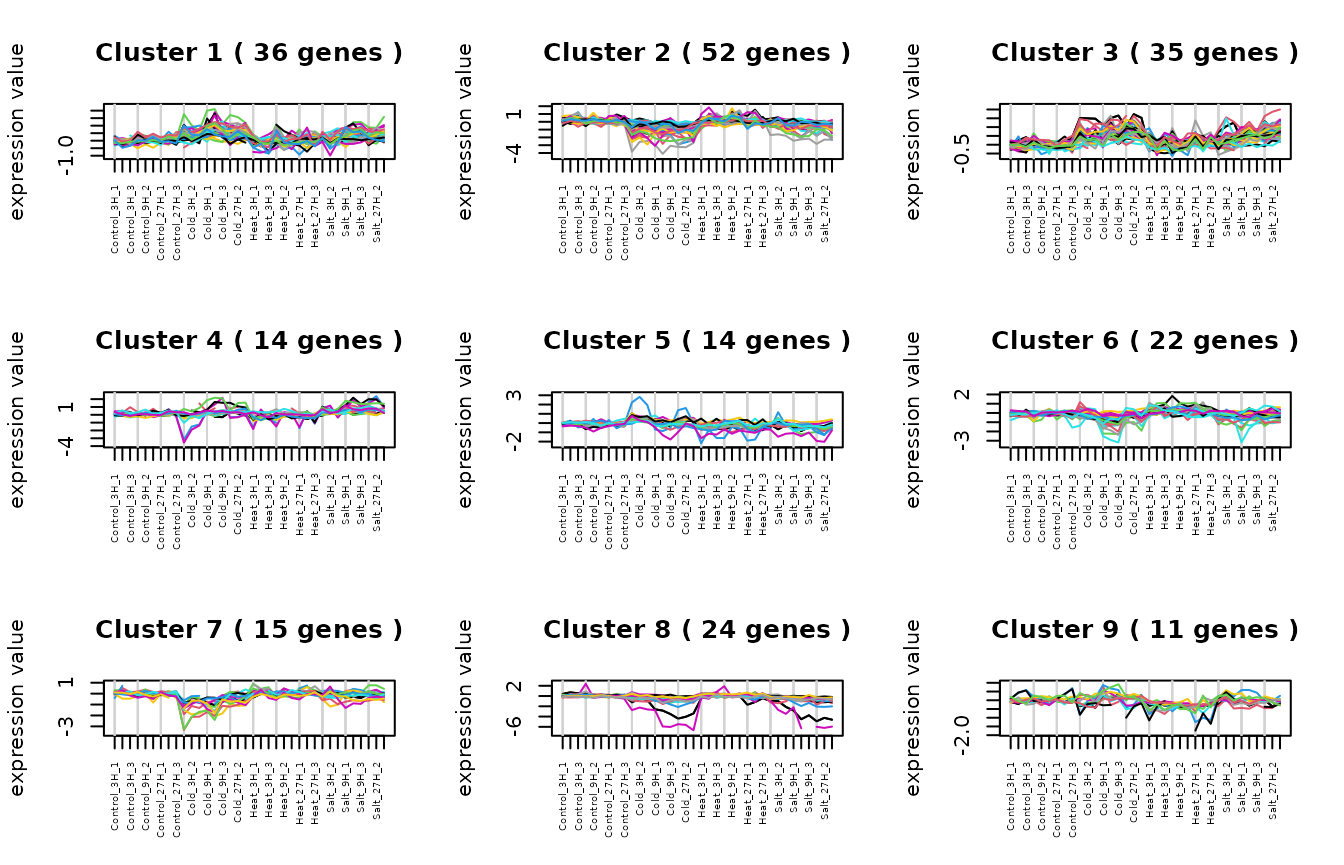

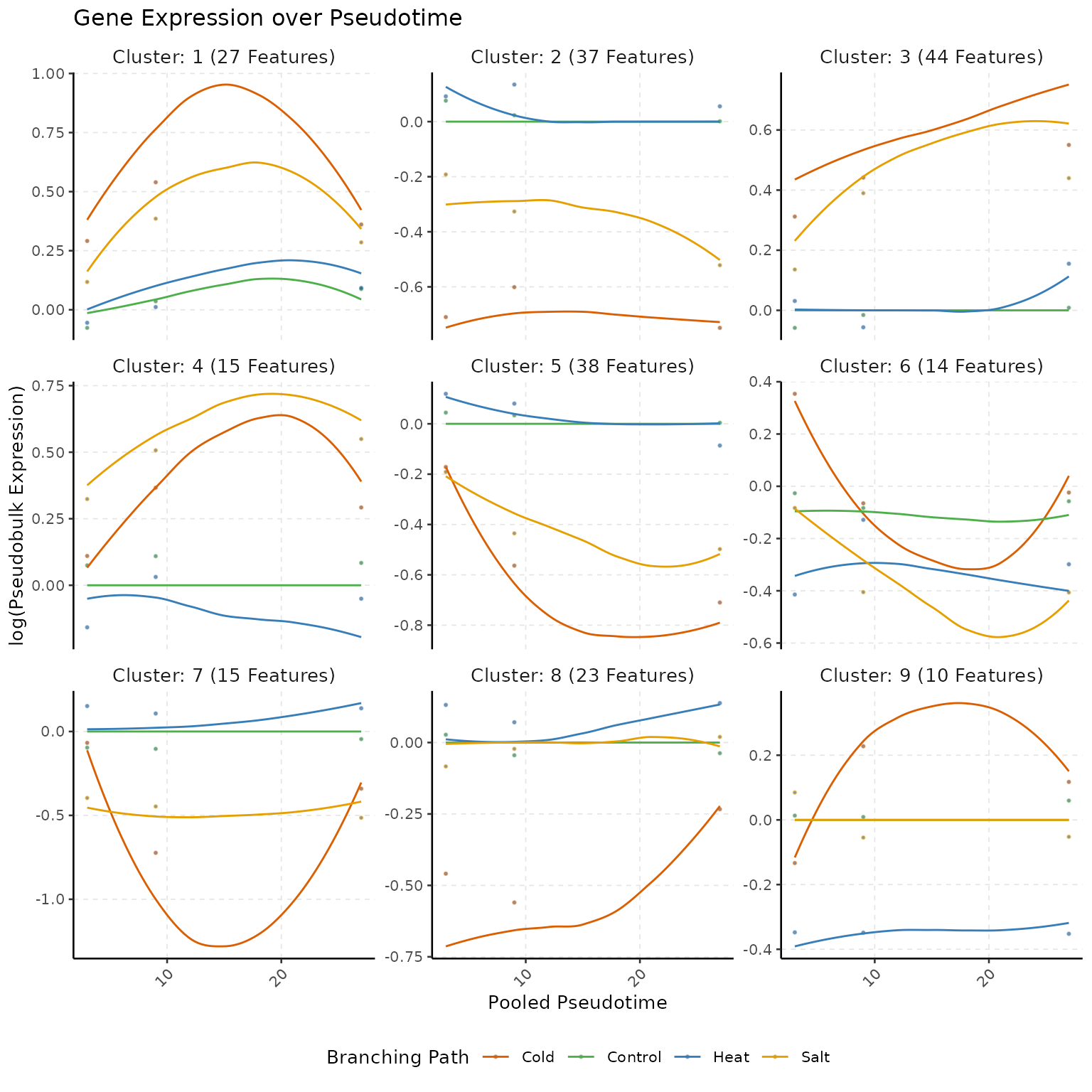
# Compute Clusters
scmp_ob <- sc.cluster.trend(scmp_ob,
geneSet = "ColdvsControl",
cluster_by = "counts"
)
Session Info
sessionInfo(package = "scMaSigPro")## R version 4.3.0 (2023-04-21)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04.5 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
## LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=es_ES.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=es_ES.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=es_ES.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=es_ES.UTF-8 LC_IDENTIFICATION=C
##
## time zone: Europe/Madrid
## tzcode source: system (glibc)
##
## attached base packages:
## character(0)
##
## other attached packages:
## [1] scMaSigPro_0.0.4
##
## loaded via a namespace (and not attached):
## [1] bitops_1.0-7 gridExtra_2.3
## [3] testthat_3.2.1 rlang_1.1.3
## [5] magrittr_2.0.3 matrixStats_1.2.0
## [7] e1071_1.7-14 compiler_4.3.0
## [9] mgcv_1.9-1 venn_1.11
## [11] systemfonts_1.0.5 vctrs_0.6.5
## [13] stringr_1.5.1 pkgconfig_2.0.3
## [15] crayon_1.5.2 fastmap_1.1.1
## [17] XVector_0.42.0 ellipsis_0.3.2
## [19] labeling_0.4.3 utf8_1.2.4
## [21] promises_1.2.1 rmarkdown_2.25
## [23] grDevices_4.3.0 UpSetR_1.4.0
## [25] ragg_1.2.7 waldo_0.5.2
## [27] purrr_1.0.2 xfun_0.42
## [29] zlibbioc_1.48.0 cachem_1.0.8
## [31] graphics_4.3.0 GenomeInfoDb_1.38.6
## [33] jsonlite_1.8.8 highr_0.10
## [35] later_1.3.2 DelayedArray_0.28.0
## [37] parallel_4.3.0 R6_2.5.1
## [39] bslib_0.6.1 stringi_1.8.3
## [41] pkgload_1.3.4 parallelly_1.37.0
## [43] brio_1.1.4 GenomicRanges_1.54.1
## [45] jquerylib_0.1.4 Rcpp_1.0.12
## [47] bookdown_0.37 assertthat_0.2.1
## [49] SummarizedExperiment_1.32.0 knitr_1.45
## [51] IRanges_2.36.0 splines_4.3.0
## [53] httpuv_1.6.14 Matrix_1.6-5
## [55] igraph_1.6.0 tidyselect_1.2.0
## [57] rstudioapi_0.15.0 abind_1.4-5
## [59] yaml_2.3.8 admisc_0.34
## [61] plyr_1.8.9 lattice_0.22-5
## [63] tibble_3.2.1 Biobase_2.62.0
## [65] shiny_1.8.0 withr_3.0.0
## [67] evaluate_0.23 base_4.3.0
## [69] desc_1.4.3 proxy_0.4-27
## [71] mclust_6.0.1 pillar_1.9.0
## [73] BiocManager_1.30.22 MatrixGenerics_1.14.0
## [75] stats4_4.3.0 plotly_4.10.4
## [77] generics_0.1.3 rprojroot_2.0.4
## [79] RCurl_1.98-1.14 S4Vectors_0.40.2
## [81] ggplot2_3.5.1 munsell_0.5.0
## [83] scales_1.3.0 BiocStyle_2.30.0
## [85] stats_4.3.0 xtable_1.8-4
## [87] class_7.3-22 glue_1.7.0
## [89] lazyeval_0.2.2 tools_4.3.0
## [91] datasets_4.3.0 data.table_1.15.0
## [93] fs_1.6.3 grid_4.3.0
## [95] utils_4.3.0 tidyr_1.3.1
## [97] methods_4.3.0 colorspace_2.1-0
## [99] SingleCellExperiment_1.24.0 nlme_3.1-164
## [101] GenomeInfoDbData_1.2.11 cli_3.6.2
## [103] textshaping_0.3.7 fansi_1.0.6
## [105] S4Arrays_1.2.0 viridisLite_0.4.2
## [107] dplyr_1.1.4 gtable_0.3.4
## [109] sass_0.4.8 digest_0.6.34
## [111] BiocGenerics_0.48.1 SparseArray_1.2.4
## [113] htmlwidgets_1.6.4 farver_2.1.1
## [115] memoise_2.0.1 maSigPro_1.74.0
## [117] entropy_1.3.1 htmltools_0.5.7
## [119] pkgdown_2.0.7 lifecycle_1.0.4
## [121] httr_1.4.7 mime_0.12
## [123] MASS_7.3-60
sessionInfo(package = "maSigPro")## R version 4.3.0 (2023-04-21)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 20.04.5 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
## LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=es_ES.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=es_ES.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=es_ES.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=es_ES.UTF-8 LC_IDENTIFICATION=C
##
## time zone: Europe/Madrid
## tzcode source: system (glibc)
##
## attached base packages:
## character(0)
##
## other attached packages:
## [1] maSigPro_1.74.0
##
## loaded via a namespace (and not attached):
## [1] bitops_1.0-7 gridExtra_2.3
## [3] testthat_3.2.1 rlang_1.1.3
## [5] magrittr_2.0.3 matrixStats_1.2.0
## [7] e1071_1.7-14 compiler_4.3.0
## [9] mgcv_1.9-1 venn_1.11
## [11] systemfonts_1.0.5 vctrs_0.6.5
## [13] stringr_1.5.1 pkgconfig_2.0.3
## [15] crayon_1.5.2 fastmap_1.1.1
## [17] XVector_0.42.0 ellipsis_0.3.2
## [19] labeling_0.4.3 utf8_1.2.4
## [21] promises_1.2.1 rmarkdown_2.25
## [23] grDevices_4.3.0 UpSetR_1.4.0
## [25] ragg_1.2.7 waldo_0.5.2
## [27] purrr_1.0.2 xfun_0.42
## [29] zlibbioc_1.48.0 cachem_1.0.8
## [31] graphics_4.3.0 GenomeInfoDb_1.38.6
## [33] jsonlite_1.8.8 highr_0.10
## [35] later_1.3.2 DelayedArray_0.28.0
## [37] parallel_4.3.0 R6_2.5.1
## [39] bslib_0.6.1 stringi_1.8.3
## [41] pkgload_1.3.4 parallelly_1.37.0
## [43] brio_1.1.4 GenomicRanges_1.54.1
## [45] jquerylib_0.1.4 Rcpp_1.0.12
## [47] bookdown_0.37 scMaSigPro_0.0.4
## [49] assertthat_0.2.1 SummarizedExperiment_1.32.0
## [51] knitr_1.45 IRanges_2.36.0
## [53] splines_4.3.0 httpuv_1.6.14
## [55] Matrix_1.6-5 igraph_1.6.0
## [57] tidyselect_1.2.0 rstudioapi_0.15.0
## [59] abind_1.4-5 yaml_2.3.8
## [61] admisc_0.34 plyr_1.8.9
## [63] lattice_0.22-5 tibble_3.2.1
## [65] Biobase_2.62.0 shiny_1.8.0
## [67] withr_3.0.0 evaluate_0.23
## [69] base_4.3.0 desc_1.4.3
## [71] proxy_0.4-27 mclust_6.0.1
## [73] pillar_1.9.0 BiocManager_1.30.22
## [75] MatrixGenerics_1.14.0 stats4_4.3.0
## [77] plotly_4.10.4 generics_0.1.3
## [79] rprojroot_2.0.4 RCurl_1.98-1.14
## [81] S4Vectors_0.40.2 ggplot2_3.5.1
## [83] munsell_0.5.0 scales_1.3.0
## [85] BiocStyle_2.30.0 stats_4.3.0
## [87] xtable_1.8-4 class_7.3-22
## [89] glue_1.7.0 lazyeval_0.2.2
## [91] tools_4.3.0 datasets_4.3.0
## [93] data.table_1.15.0 fs_1.6.3
## [95] grid_4.3.0 utils_4.3.0
## [97] tidyr_1.3.1 methods_4.3.0
## [99] colorspace_2.1-0 SingleCellExperiment_1.24.0
## [101] nlme_3.1-164 GenomeInfoDbData_1.2.11
## [103] cli_3.6.2 textshaping_0.3.7
## [105] fansi_1.0.6 S4Arrays_1.2.0
## [107] viridisLite_0.4.2 dplyr_1.1.4
## [109] gtable_0.3.4 sass_0.4.8
## [111] digest_0.6.34 BiocGenerics_0.48.1
## [113] SparseArray_1.2.4 htmlwidgets_1.6.4
## [115] farver_2.1.1 memoise_2.0.1
## [117] entropy_1.3.1 htmltools_0.5.7
## [119] pkgdown_2.0.7 lifecycle_1.0.4
## [121] httr_1.4.7 mime_0.12
## [123] MASS_7.3-60